
Swiss Federal Archives
Turning 10,000 WWII prisoner-of-war cards into a searchable historical resource.


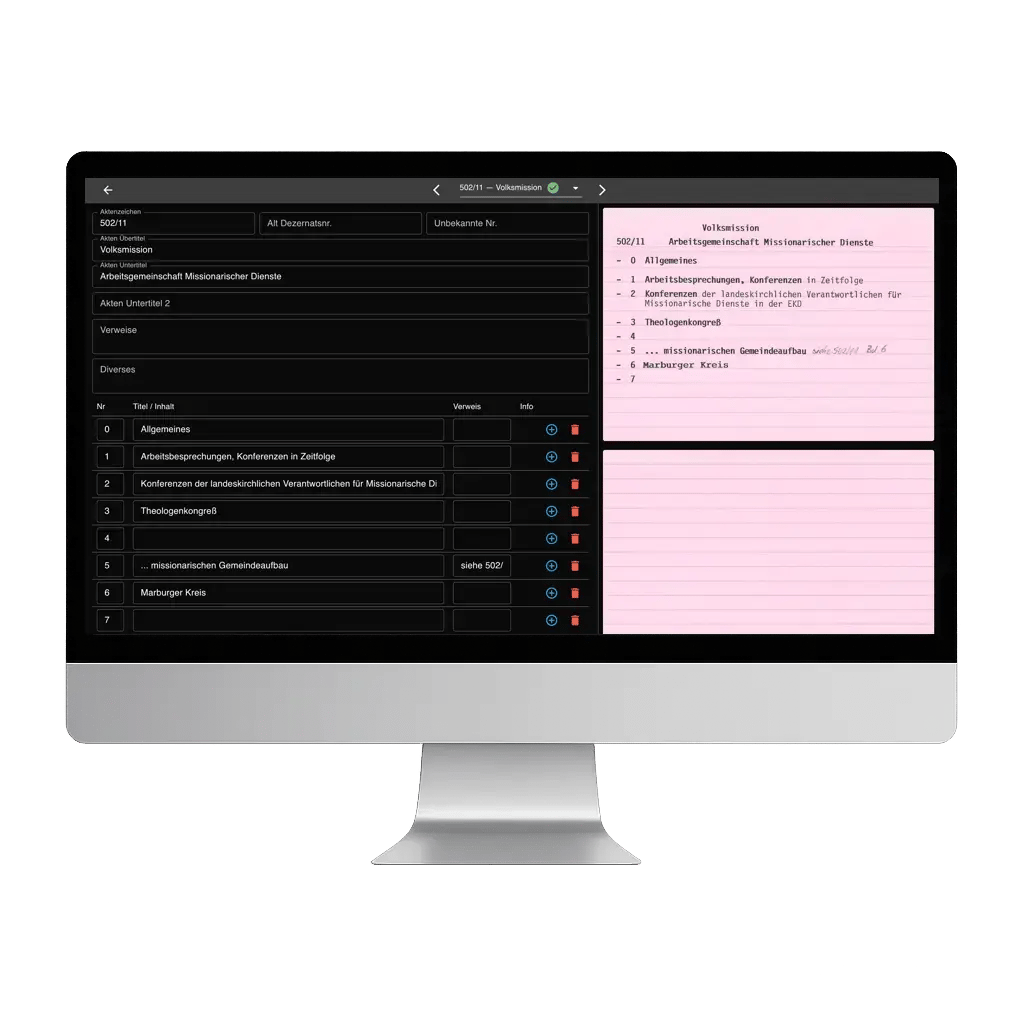
Next, AI extracts the things that matter – names, dates, places, organisations and keywords – and places them into structured fields. Archivists review and refine these fields in a quality-review dashboard, checking them against the original scans. Once reviewed, the cleaned data is exported into archival information systems or research databases to support ongoing work.

Optionally, we design a search interface tailored to your needs. Staff and researchers can run free-text or fielded searches across the whole dataset, with each result linking back to its original digitised record for context and verification. This makes it much easier to spot patterns and connections across entire collections.
Turning 10,000 WWII prisoner-of-war cards into a searchable historical resource.
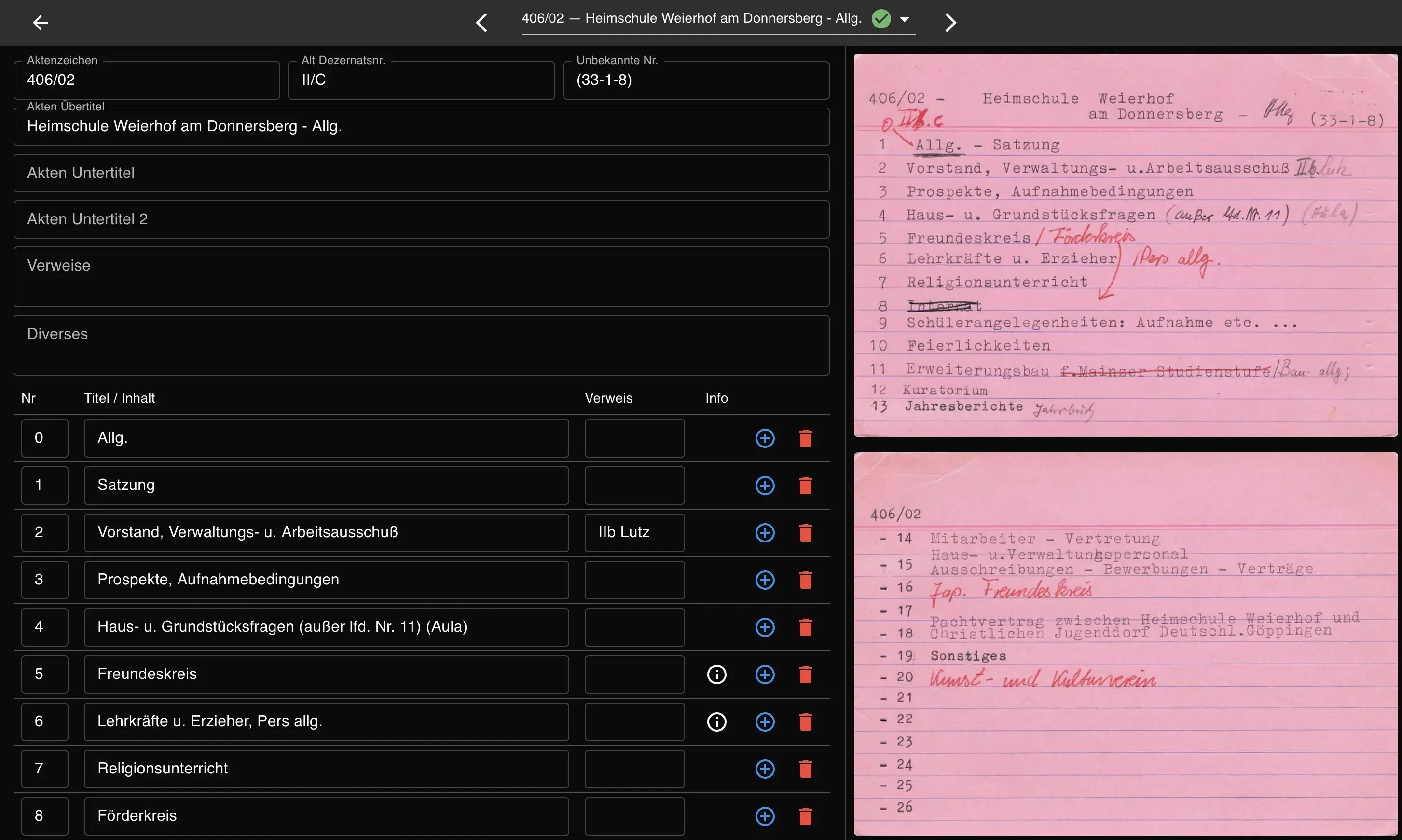
In just a few weeks 1,548 registry cards went from a physical collection to searchable digital records.

Using AI to speed up cataloguing of 19th-century children’s books.

For collections that are carefully preserved but searchable only item by item, metadata extraction transforms what's possible. Researchers can search across an entire collection - by name, date, place, or theme - and find answers in minutes instead of months. If you're interested in how our clients are using it, explore our case studies.