
Schweizerisches Bundesarchiv
20’000 Kriegsgefangenen-Karteikarten aus dem Zweiten Weltkrieg wurden zum einfach nutzbaren Bestand.


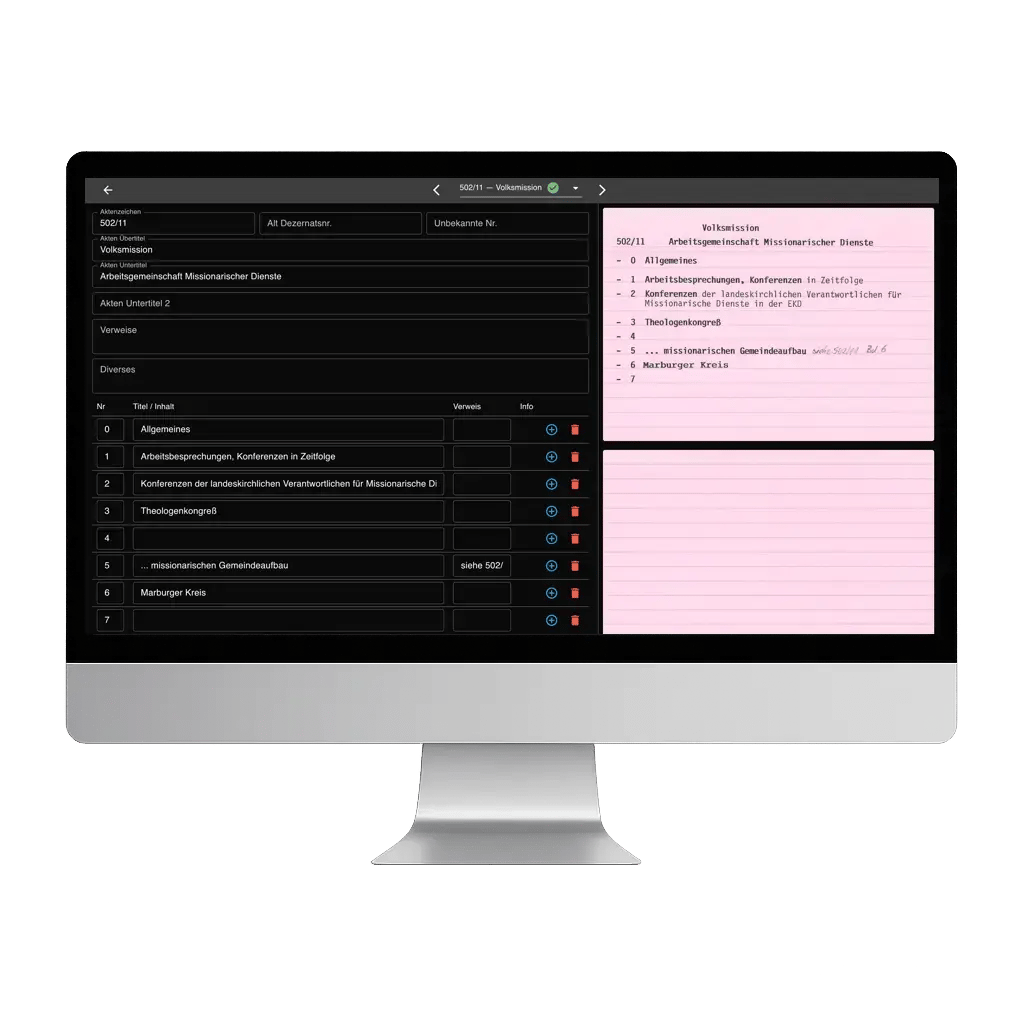

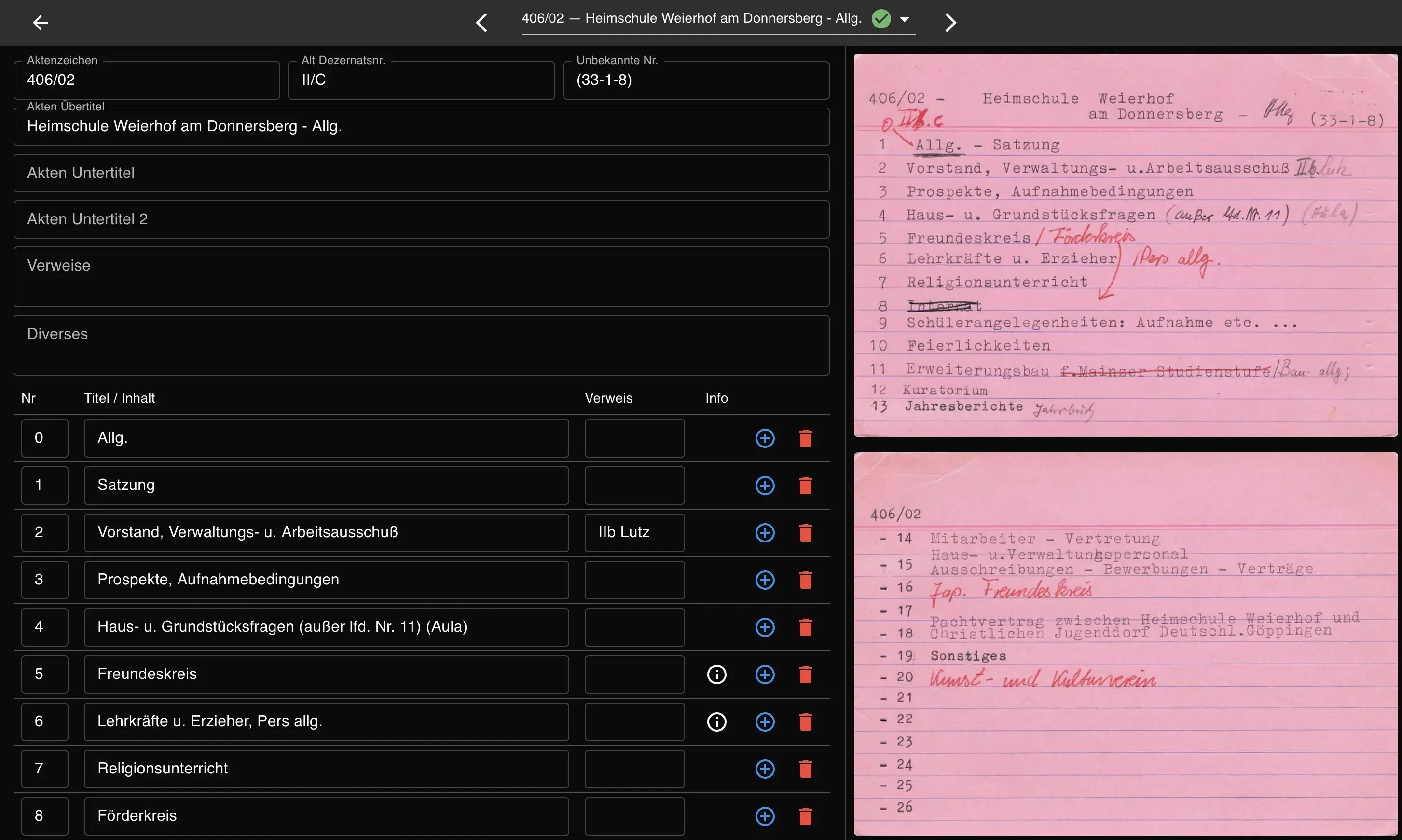
Innerhalb weniger Wochen wurden 1’548 Registerkarten von einem physischen Bestand in durchsuchbare digitale Datensätze überführt.

Einsatz von KI zur Beschleunigung der Katalogisierung von Kinderbüchern des 19. Jahrhunderts.

Für Bestände, die sorgfältig bewahrt werden, aber nur einzeln recherchierbar sind, eröffnet Metadatenextraktion neue Möglichkeiten. Forschende können über ganze Bestände hinweg suchen – nach Namen, Daten, Orten oder Themen – und erhalten Ergebnisse in Minuten statt in Monaten. Wenn Sie sehen möchten, wie unsere Kundinnen und Kunden dies nutzen, entdecken Sie unsere Fallstudien.