
Archives fédérales suisses
Transformation de 20’000 fiches de prisonniers de guerre de la Seconde Guerre mondiale en fond facile à utiliser.


Les outils de reconnaissance optique de caractères (OCR) et de reconnaissance de l’écriture manuscrite convertissent des documents imprimés et manuscrits numérisés en texte lisible par machine. Cela constitue la base pour la recherche et l’analyse à travers fiches, registres, manuscrits et autres types de documents.
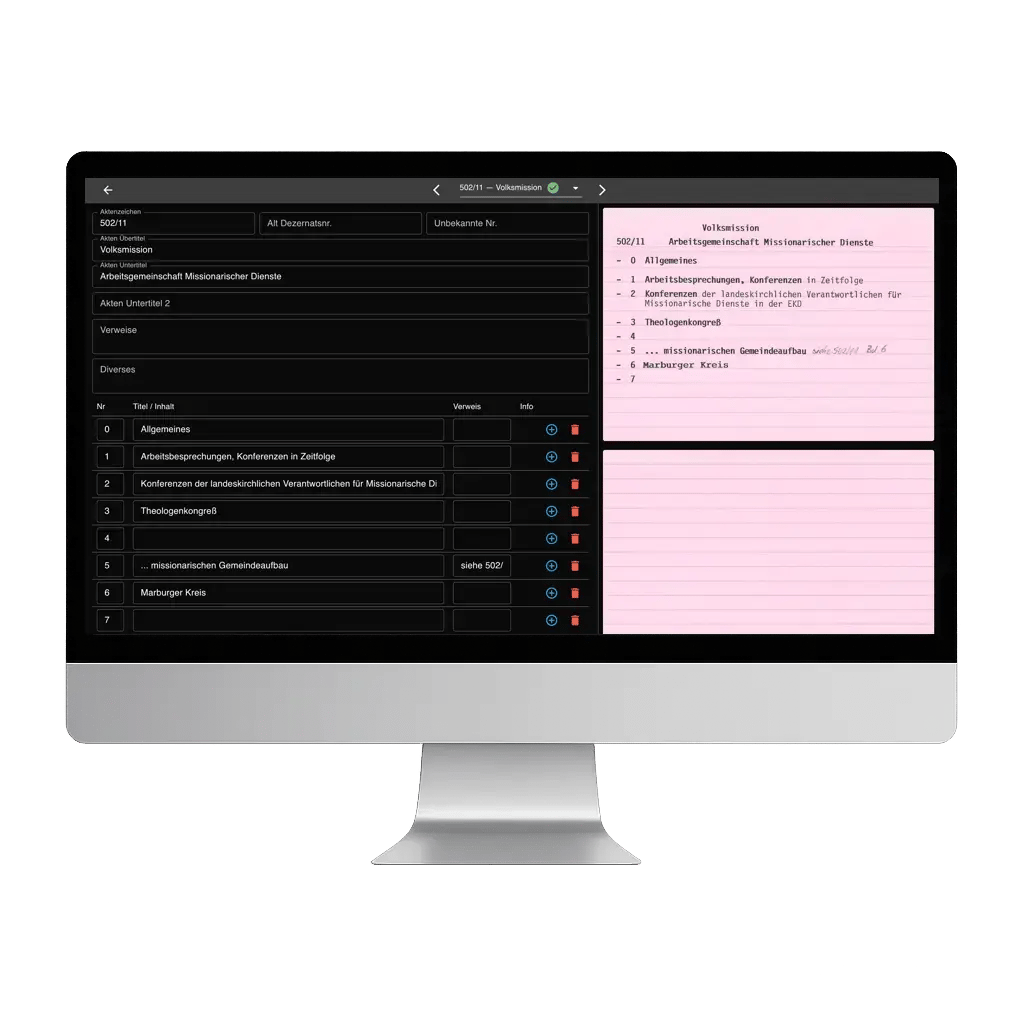
L’IA extrait ensuite les éléments essentiels — noms, dates, lieux, organisations et mots-clés — et les place dans des champs structurés. Le personnel archivistique examine et affine ces champs dans une interface de contrôle qualité, en les comparant aux documents numérisés d’origine. Une fois validées, les données nettoyées sont exportées vers des systèmes d’information archivistique ou des bases de données de recherche afin de soutenir le travail en cours.

En option, nous concevons une interface de recherche adaptée à vos besoins. Le personnel et les chercheurs peuvent effectuer des recherches en texte libre ou par champs sur l’ensemble du jeu de données, chaque résultat renvoyant vers le document numérisé d’origine pour le contexte et la vérification. Cela facilite l’identification de motifs et de liens à l’échelle de collections entières.
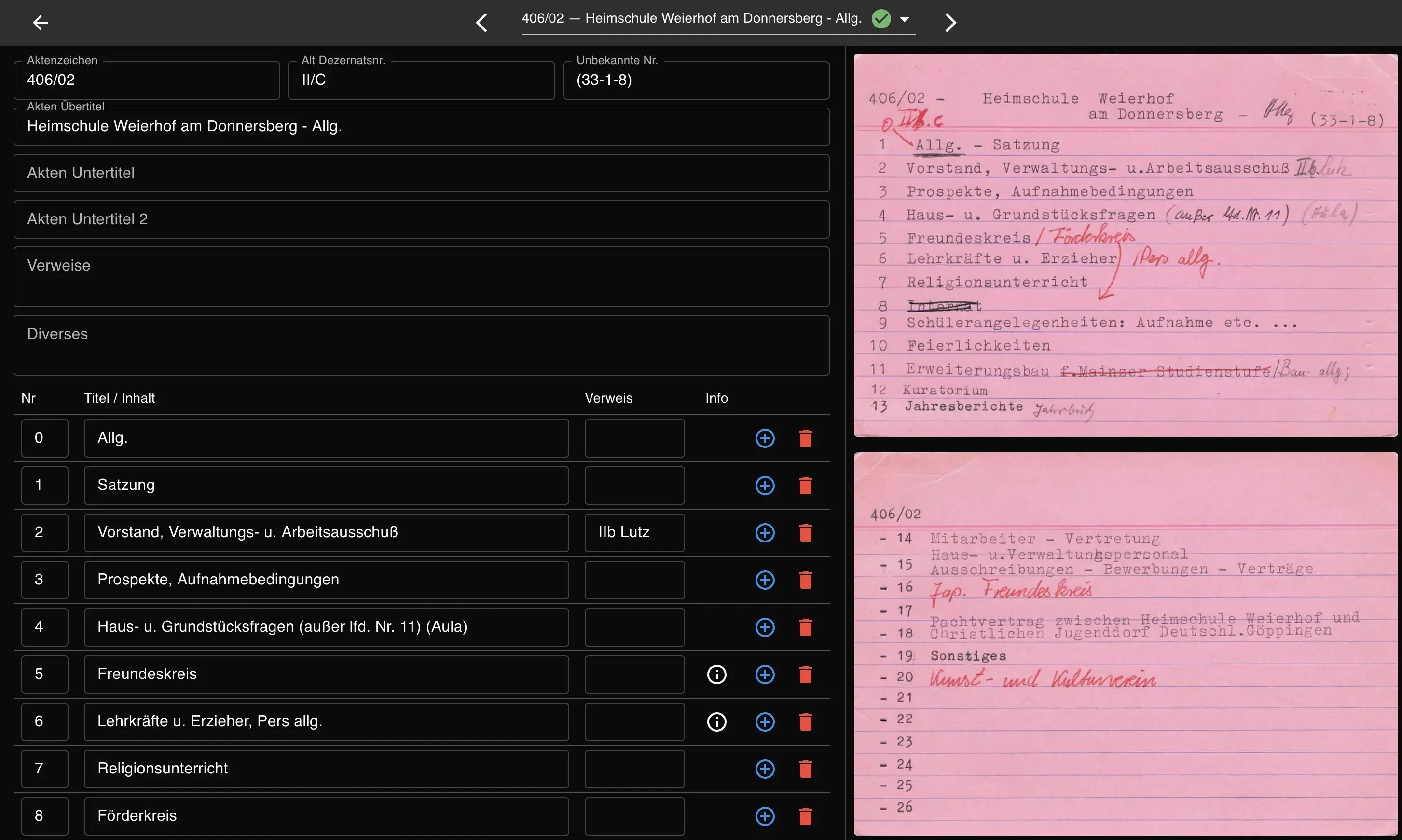
En quelques semaines seulement, 1’548 fiches de registre sont passées d’une collection physique à des enregistrements numériques interrogeables.

Utilisation de l’IA pour accélérer le catalogage de livres pour enfants du XIXe siècle.

Pour des collections soigneusement conservées mais consultables uniquement document par document, l’extraction de métadonnées change ce qui est possible. Les chercheurs peuvent effectuer des recherches sur l’ensemble d’une collection — par nom, date, lieu ou thème — et obtenir des réponses en quelques minutes plutôt qu’en plusieurs mois. Si vous souhaitez voir comment nos clients l’utilisent, découvrez nos études de cas.