 Understanding AI in Archiving. Source: DALL·E 3
Understanding AI in Archiving. Source: DALL·E 3
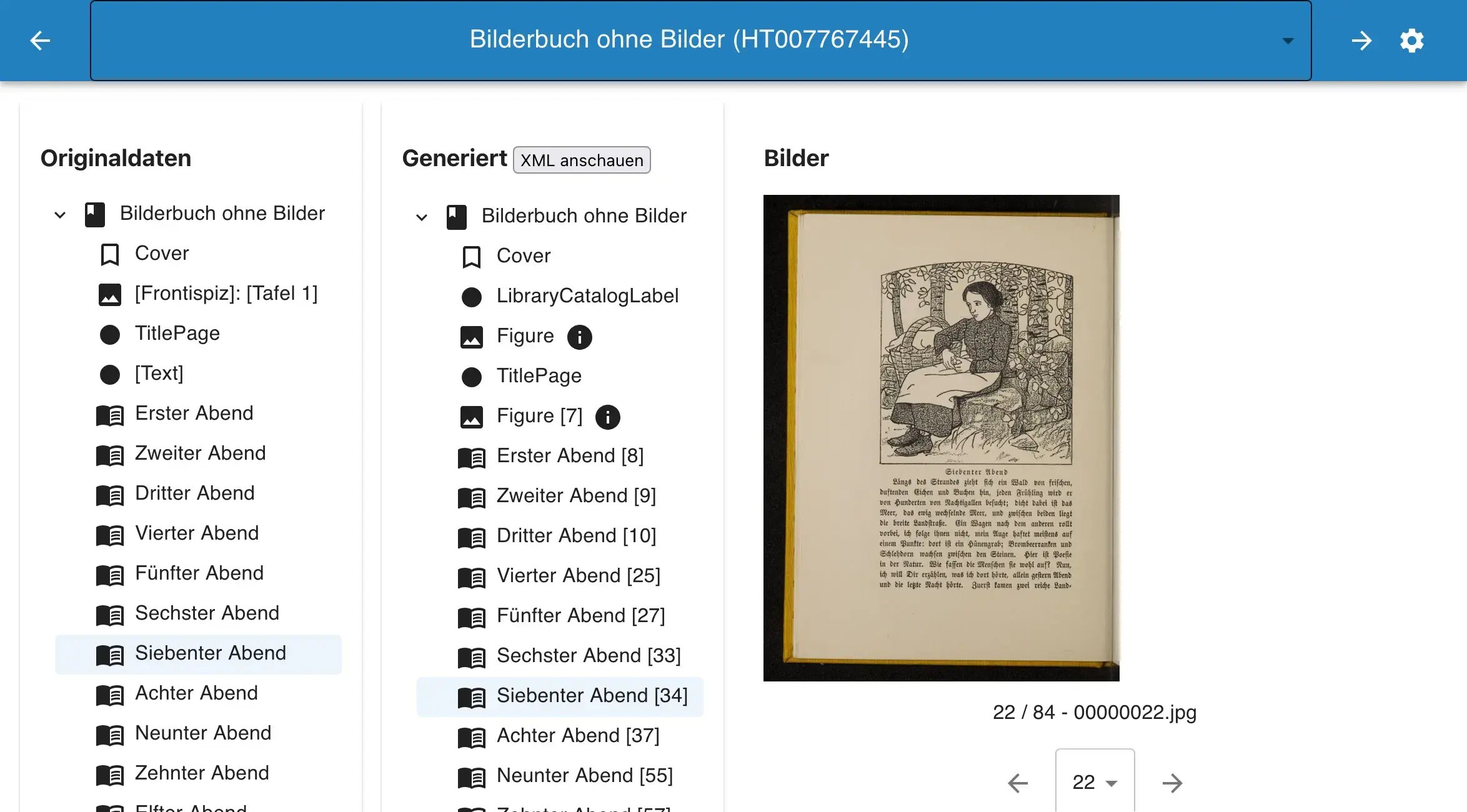
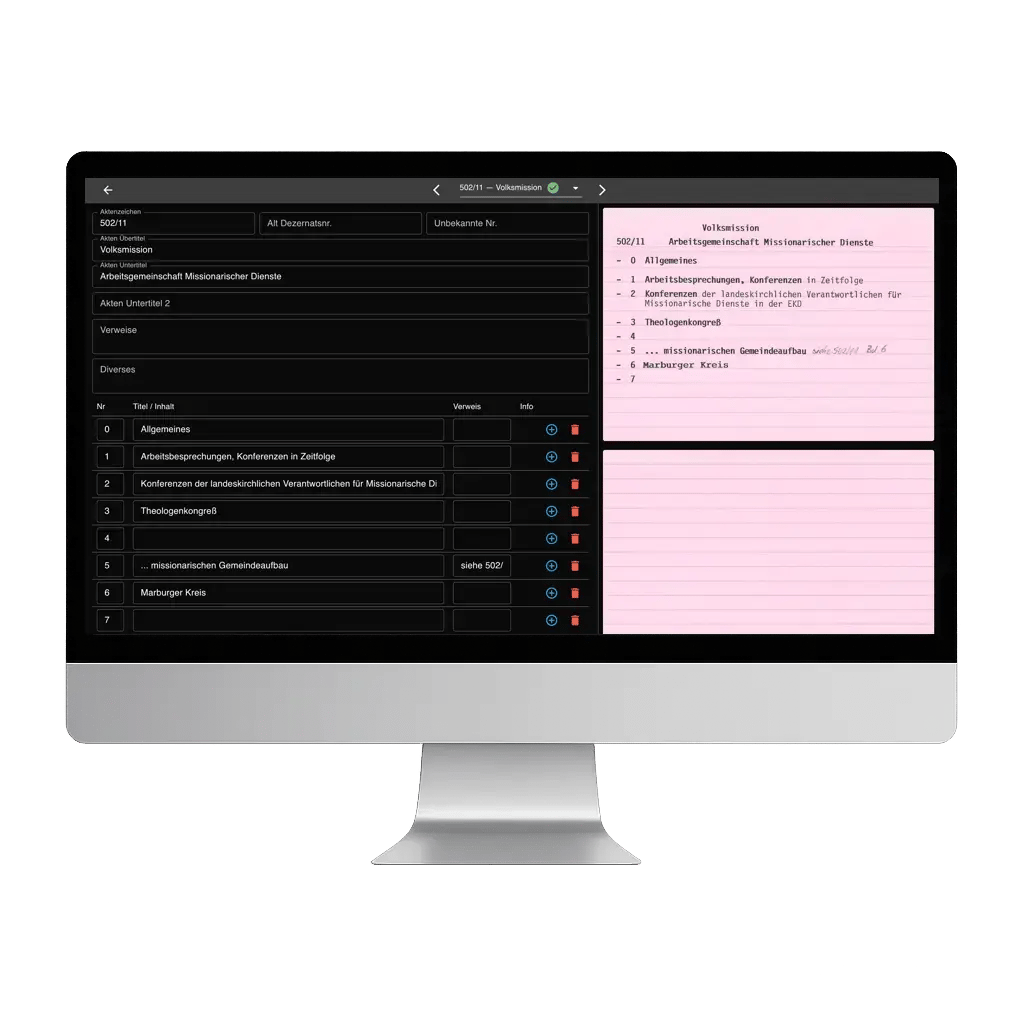
Künstliche Intelligenz (KI) hat sich zu einem leistungsfähigen Werkzeug in Bereichen wie dem Archiv- und Bibliothekswesen entwickelt. Bei Archipanion nutzen wir die Möglichkeiten der KI, um die Nutzung und und Zugänglichkeit umfangreicher multimedialer Sammlungen zu erleichtern. Es stellt sich jedoch die Frage: "Wie können wir KI trainieren, um so vielfältiges Material zu Material verstehen kann?" Im Folgenden werden einige Details des KI-Trainings und seiner Bedeutung für Archive und Bibliotheken erläutert.
Die Grundlage der KI: Daten und Lernen
Das Herzstück der KI ist ein Modell, eine mathematische Struktur, die aus Daten lernt. Stellen Sie sich einen eifrigen Schüler vor, der in ein Klassenzimmer voller historischer und zeitgenössischer Dokumente, Fotografien und Filme eintaucht. So wie ein Schüler Wissen aus Lehrbüchern und Erfahrungen aufnimmt, lernt unser KI-Modell, indem es eine Vielzahl von Multimedia-Inhalten analysiert.
Wie wird künstliche Intelligenz trainiert?
Stellen Sie sich unsere KI als eine Mischung aus Historiker und Linguist vor. Sie untersucht Bilder und verarbeitet gleichzeitig die begleitenden Textbeschreibungen (z.B. Bildunterschriften). Bei jeder Begegnung stellt sie Verbindungen zwischen bestimmten Wörtern und Sätzen und visuellen Elementen her. Trifft sie beispielsweise auf zahlreiche Gemälde, auf denen das Wort "Impressionismus" vorkommt, beginnt sie, die charakteristische Pinselführung und den Einsatz von Licht zu erkennen.
Das Modell der künstlichen Intelligenz: ein visueller und sprachlicher Experte
Das von uns verwendete Machine-Learning-Modell ist sehr gut in der Lage, diese Art von Assoziationen zu bilden. Es ist wie ein persönlicher Assistent, der sowohl ein visueller Spezialist als auch ein Sprachtalent ist und darauf trainiert wurde, die Verbindung zwischen visuellen und textuellen Daten herzustellen.
Training unserer KI: Ein vielfältiges Spektrum an Daten
Die KI, die wir derzeit verwenden, wurde mit einer Vielzahl von Bild- und Videodatensätzen trainiert:
- Flickr30k: In 31.000 Bildern sind alltägliche Szenen festgehalten und beschriftet.
- Microsoft COCO: Über eine Million Bilder, fokussiert auf Objekterkennung.
- MSRVTT: 10.000 Videoclips mit sprachlichen Annotationen, die Videoinhalte mit Wörtern verknüpfen.
- TextCaps and TGIF: Spezialisiert auf das Verständnis komplexer Bildunterschriften und animierte GIFs.
- VaTeX: Nutzt 41.250 mehrsprachige Videoclips und erweitert die Sprachfähigkeiten unserer KI.
- ImageNet: Biete eine Kategorisierung von ca. 50 Millionen Bildern.
Zusammen bieten diese Datensätze ein reichhaltiges Abbild des Lebens, der Kultur und der Sprache, das für die Entwicklung einer KI zur Unterstützung von Archivaren und Bibliothekaren bei der Verwaltung und Interpretation ihrer Sammlungen wichtig ist.
Unsere aktuelle KI-Forschung: Mehrsprachiges Verstehen auf hohem Niveau
In unserem ständigen Streben nach Innovation im Bereich der KI arbeiten wir mit der Universität Basel zusammen, um fortschrittliche KI-Methoden zu erforschen und zu testen. Diese Partnerschaft ist wichtig für unsere Bemühungen, die Fähigkeit der KI zu verbessern, mehrere Sprachen zu verstehen. Unser Ziel ist es, verschiedene Modelle zu testen und zu validieren, die unser derzeitiges System in der mehrsprachigen Verarbeitung übertreffen. Diese Forschung ist ein wichtiger Teil unserer Mission, Archive und Bibliotheken zugänglicher und inklusiver zu machen, um letztendlich die Reichweite und den Nutzen dieser wichtigen Bestände zu erhöhen..
Das menschliche Fachwissen: Eine unverzichtbare Grundlage
KI ist zwar ein leistungsfähiges Werkzeug, ersetzt aber nicht die Fachkenntnisse von Archivaren und Bibliothekaren. Stattdessen dient sie als wertvoller Verbündeter, der grosse Datenmengen verarbeitet und Informationen generiert. So können sich Archivare und Bibliothekare auf die nuancierten und interpretativen Aspekte ihrer Arbeit konzentrieren, die menschliches Urteilsvermögen erfordern.
Fazit: Archipanion: AI als Compagnon für Archive und Bibliotheken
Wir bei Archipanion haben es uns zur Aufgabe gemacht, die Handhabung, Nutzung und den Zugang zu Archivbeständen zu vereinfachen. Unser Ziel ist es, Archive in lebendige, intelligente Plattformen zu verwandeln, die Geschichte und Wissen zum Leben erwecken. Durch die Kombination von maschinellem Lernen und archivarischem Fachwissen ermöglicht Archipanion Gedächtnisinstitutionen, das grosse Potenzial ihrer Bestände auszuschöpfen. Durch diesen kollaborativen Ansatz streben wir danach, den grossen Wert historischer Sammlungen einfach nutzbar zu machen. Eine Zusammenarbeit, die sicherstellt, dass unser gemeinsames Erbe erhalten bleibt, verstanden wird und für alle leicht zugänglich ist.